

Introduction
This article is about the term project I carried out in the machine learning course. I chose the data set of parkinsons telemonitoring. This dataset was created by Atanasios Tsanas and Max Little of Oxford University in collaboration with 10 U.S. medical centers and Intel Corporation. Originally, this study used various linear and nonlinear regression methods to predict clinicians' Parkinson's disease symptom scores on UPDRS scales, and I also tries to predict the Unified Parkinson's Disease Rating Scale (UPDRS) of clinicians with Deep Neural Network (DNN).
Information of data
This data set consists of a range of biomedical negative measurements of 42 people with early-stage Parkinson's disease. The following is a description of the names of all variables in the dataset and their use. In 'parkinsons_updrs.data', there are 22 attributes and 5875 instances. Among them, motor_UPDRS and total_UPDRS are target variables. motor_UPDRS is the motor UPDRS score of clinicians and total_UPDRS is the total UPDRS score of clinicians.
subject# is an integer that uniquely identifies each subject, so each person has its own number.
age is an age of each subject, and sex is the gender of each subject. ('0' is male, '1' is female)
test_time is the time since recruitment into the trial and the integer part is the number of days since recruitment. Jitter(%), Jitter(Abs), Jitter:RAP, Jitter:PPQ5, Jitter:DDP are some measurements of the variation in the default frequency. Shimmer, shimmer(dB), Shimmer:APQ3, Shimmer:APQ5, Shimmer:APQ11, Shimmer:DDA are several mesurements of variation in amplitude. NHR, HNR are measurements of noise ratio for tone components of voice. PRDE is a non-linear dynamical complexiry measurement. DFA is exponent of signal fractal scaling. PPE is a non-linear measurement of fudamental frequency variation.
Of the total data, I split the data into train data(70%) and test data(30%). Also, I normalized the data to avoid the problem if the scale of the features that the data is significantly different.
With Pytorch's Dataset and Dataloader, we can process vast amounts of learning in batch units, reducing losses. Therefore, I made two classes for dividing dataset into train dataset and test dataset: ParkinsonsTrainDataset, ParkinsonsTestDataset. The dataloader we make is divided into three parts.
1. __init__(self) is the part where data is read or downloaded.
2. __getitem__(self, index) is the part that hands over the item corresponding to the index.
3. __len__(self) is the part that passes the size of the data.
class ParkinsonsTrainDataset(Dataset):
def __init__(self):
xy = np.loadtxt('./parkinsons_updrs.data',
delimiter=',', skiprows=1, dtype=np.float32)
train_len = int(xy.shape[0] * 0.7)
train_xy = xy[:train_len]
self.len = train_xy.shape[0]
y_label_indx = [5, 6]
self.train_x = np.delete(train_xy, y_label_indx, axis=1)
self.train_x = torch.from_numpy(self.train_x)
self.train_y = torch.from_numpy(train_xy[:, y_label_indx[0]: y_label_indx
[1] + 1])
self.train_x, mu, sigma = normalize(self.train_x)
self.train_y, mu, sigma = normalize(self.train_y)
def __getitem__(self, index):
return self.train_x[index], self.train_y[index]
def __len__(self):
return self.len
When creating a dataloader to train, put the class we made in the dataset.
train_dataset = ParkinsonsTrainDataset()
test_dataset = ParkinsonsTestDataset()
train_loader = DataLoader(dataset=train_dataset,
batch_size=32,
shuffle=True,
num_workers=0, drop_last=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=32,
num_workers=0)
Approach
I predicted the UPDRS score after learning from the Deep Neural Network (DNN) model, which is made of multiple Full Connected (FC) layers with regression problem.

Deep Neural Network (DNN) is an artificial neural network consisting of multiple hidden layers between the input layer and output layer, which significantly increases the hidden layer to improve the learning outcomes. DNN is being used as a key model for deep learning as methods such as dropout, Rectified Linear Unit(ReLU) are applied. DNN allows only a smaller number of units to model complex data.
I decided the hidden nodes to 300, so input nodes are 20 and ouput nodes are 2. Also, I decided the loss function to use Mean Squared Error (MSE) and optimizer. When SGD is used by calling model.parameters(), the layers of the model hand over the parameters to be learned. By the way, I chose 0.0001 for learning rate.
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.l1 = nn.Linear(20, 300)
self.relu = nn.ReLU()
self.l2 = nn.Linear(300, 2)
def forward(self, x):
out1 = self.l1(x)
out2 = self.relu(out1)
out = self.l2(out2)
return out
model = Model()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.0001)
Training
Before predicting, we need to train the model. There was a large difference in scale between the Total_UPDRS loss and Motor_UPDRS loss, so the Motor_UPDRS loss was multiplied by weight(3).
for epoch in range(30):
for i, data in enumerate(train_loader):
inputs, labels = data
y_pred = model(inputs)
motor_updrs_mse = criterion(y_pred[:, 0], labels[:, 0])
total_updrs_mse= criterion(y_pred[:, 1], labels[:, 1])
total_loss = 3 * motor_updrs_mse + total_updrs_mse
print(f'Epoch {epoch + 1} | Step: {i+1} | Loss: {total_loss.item():.4f}')
optimizer.zero_grad()
total_loss.backward()
optimizer.step()

Prediction
After training, the result of average of all UPDRS mse, Motor_UPDRS mse and Total_UPDRS mse is below.

Whenver the modeling, the all UPDRS mes value kept changing a lot, so I fixed the initial value.
torch.manual_seed(1234)
The left graph is the result of predicting the Motor_UPDRS and the right graph is the result of predicting the Total_UPDRS. Total_UPDRS is very well predicted, but Motor_UPDRS is a little incomplete. As I will tell you later in the conclusion, I struggled a little to improve the performance of the Motor_UPDRS prediction.
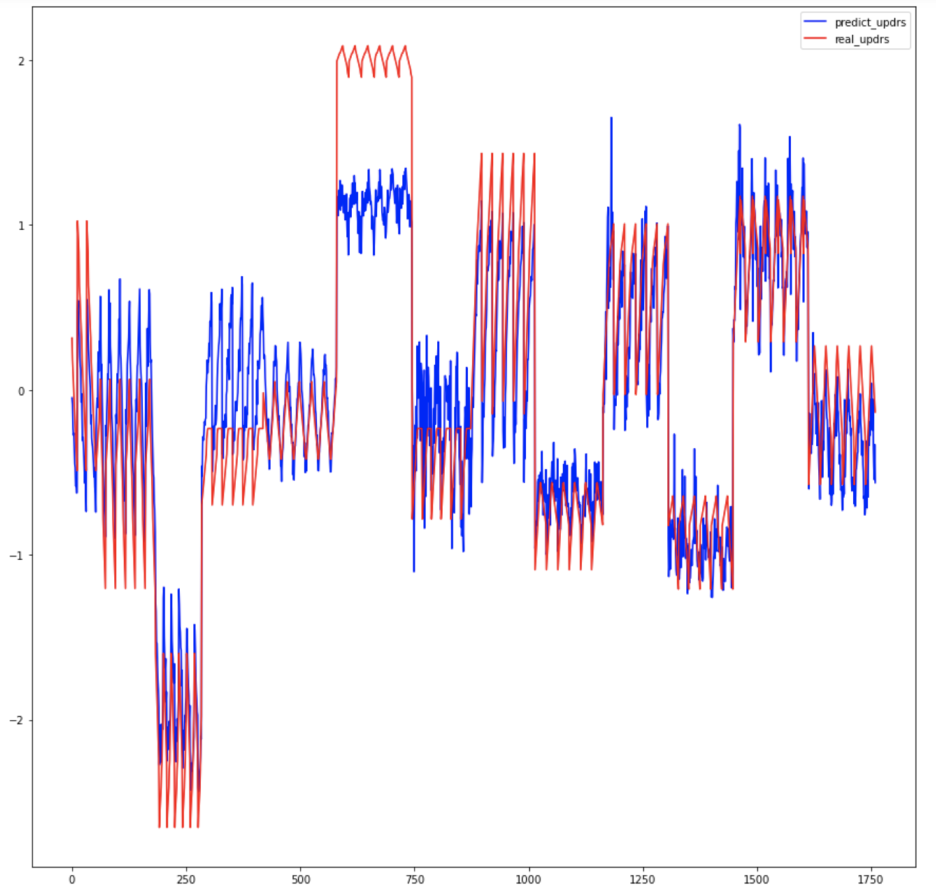

Conclusion
To be honest, the process of doing this project was not easy. I've run into several failures. Initially, the data was not normalized and then tried to make predictions after modeling, so the value scale was too large to be predicted properly. In particular, the Total_UPDRS value was poorly predicted because the loss was significantly less than the loss of Motor_UPDRS. So I realized the importance of regularization.
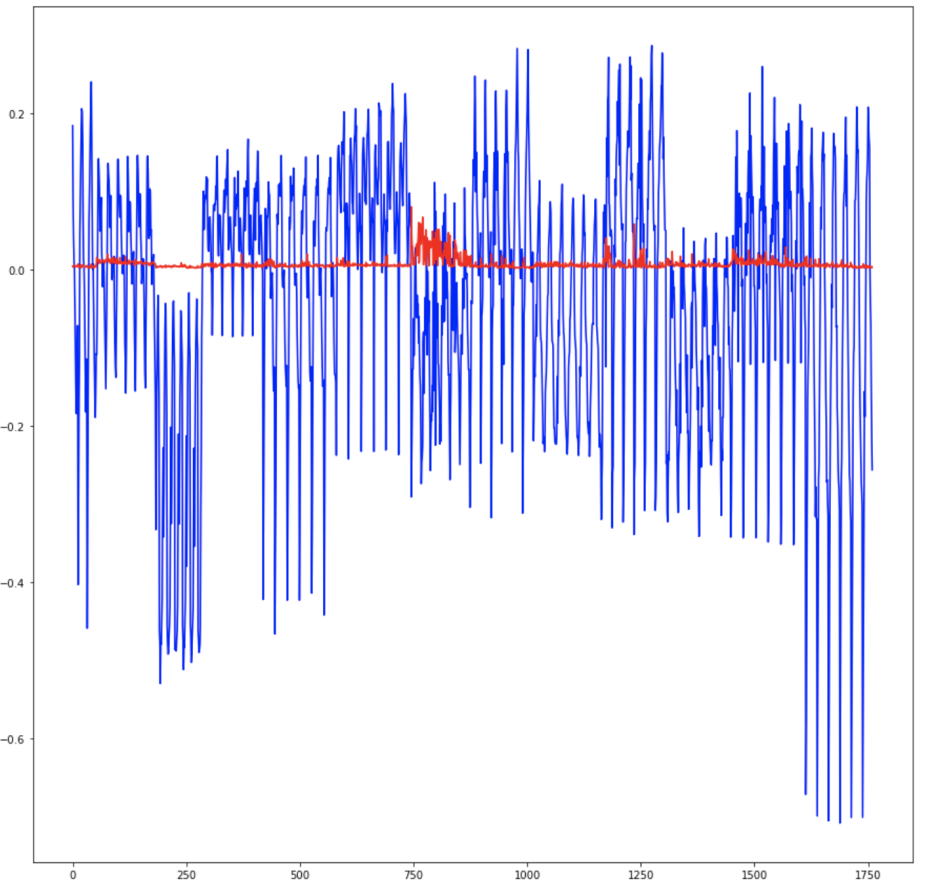
After regularizing the data, it seemed to be somewhat predictable, but it was difficult to find a proper standard to predict both Motor_UPDRS and Total_UDPRS. Although the normalization made the value smooth to some extent, I multiplied Motor_UPDRS loss by weight because it needed to be predicted at the level of Motor_UPDRS only, and only then the prediction was good. Of course, there are still some parts that are not good prediction.
Reference
Telemonitoring of Parkinson's disease progression by non-invasive speech tests. (n.d.). Retrieved December 26, 2020, from https://www.neuraldesigner.com/learning/examples/parkinsons-disease-telemonitoring